Co-founder & Design Lead · 2025 · Reyda
Designing clarity into complex procurement operations
Reducing cognitive load in document-heavy procurement processes through unified discovery, AI-powered comprehension, and guided qualification
Reducing cognitive load in document-heavy procurement processes through unified discovery, AI-powered comprehension, and guided qualification
8× more tenders pursued in the same working hours
Measured in a single-company pilot and held across five more. Qualification stopped being a bottleneck, and time shifted from interpretation to decision-making. This produced a fundamentally different process rather than a faster version of the old one.
Earlier go/no-go decisions
Teams are able to assess viability within hours instead of days, reducing time spent on low-fit opportunities and moving from reactive response to intentional selection.
Funded by investors
I presented the thesis directly to investors, walking them through the problem framing, the pilot data, and the product direction. The product secured early funding, validating both the problem space and the commercial potential of the approach.
EU public procurement is a €2 trillion market, roughly 14% of GDP, and open to any qualifying company across all member states. Tenders are standardised and consistently published. On paper, access is not the problem, but participation tells a different story.
Single-bidder tenders increased from 23.5% in 2011 to 41.8% by 2021. Cross-border participation remains below 5%. SMEs win most contracts by count, but far less by value. Companies either drop out early or do not complete the process.
The workflow has been digitised without being simplified. Teams still read through long documents, extract requirements manually, and rebuild structure before they can make a decision. That work happens before anything meaningful starts, and between a published tender and a go or no-go decision, there is a large amount of manual interpretation that repeats across every opportunity.
My co-founder and I started with a simple assumption: improving how teams discover and track tenders would increase participation. I worked closely with a mid-sized EU procurement team, sitting in live bid meetings and shadowing active tenders, and focused on the parts of the workflow that do not appear in process documents, the re-reads, the backtracking, the points where teams quietly stop.
To test whether this held beyond one team, I spoke to 24 procurement professionals across six EU countries, across both public and private sectors. The same patterns showed up.
Across teams, the goal was consistent: move from discovery to submission faster than competitors, and progress depended on how quickly a team could piece together what mattered.
Looking across countries, the workflow itself stayed largely the same, but the differences sat in the surrounding infrastructure: multiple portals, inconsistent formats, and fragmented submission systems. The effort required to reach clarity remained constant.
The pressures were consistent across teams. Titles varied, responsibilities overlapped, and in many cases one person operated across multiple roles depending on the stage of the tender. What changed was not the goal, but where each role felt the friction most.

As a procurement manager, I need to determine whether a tender is worth pursuing, so that I can avoid spending time on opportunities we will not win.

As a bid manager, I need to understand key requirements without reading everything, so that I can assess viability within hours instead of days.

As a project lead, I need to identify what is missing early, so that I can avoid late-stage blockers and rework.

As a bid team member, I need to move from evaluation to response without starting from scratch, so that we can act quickly when an opportunity is a strong fit.
To understand where to differentiate, I looked across tools used in procurement workflows.
Most legacy products supported parts of the process, but the gaps were consistent.
Discovery was handled by portals and alert systems. Response was supported by workflow tools and proposal generators. The breakdown sat in between, as understanding and qualification remained manual.
Understanding and qualification are the slowest and most uncertain parts of the workflow
Existing tools support discovery and response, but leave the middle unstructured
Teams spend most of their time building clarity before making a decision
Speed of understanding directly affects whether teams can act on opportunities
Legacy tools are not designed for the volume and complexity of tender data
Processing documents remains manual despite digitisation
Access to documents does not equal understanding
Availability has improved, but interpretation effort has not
AI is often layered on top of existing workflows rather than embedded into them
It generates outputs but does not reduce upstream effort
Most tools focus on output generation rather than decision support
They help write proposals, but not determine whether to pursue them
The ecosystem is fragmented across countries
Tools are built around national systems, limiting cross-border participation
Infrastructure varies, but the underlying workflow remains the same
Teams face similar problems regardless of country or sector
Repetitive work persists across stages
Information is restructured, rewritten, and re-entered multiple times
Data is not retained or reused effectively
Each tender starts with limited reference to past work or existing knowledge
Based on the procurement team I shadowed, the steps below reflect how work actually happens end to end. The main friction shows up at qualification, where teams have to interpret requirements and map them to internal capabilities. Most of the time is spent building enough clarity to decide whether to proceed.
Total time from discovery to submission: 2 to 6+ weeks. Most of this effort is spent before any meaningful decision is made.
Using the mapped workflow as a reference point, I identified where the experience could be fundamentally improved, not by fixing individual steps, but by removing the points where teams slowed down, lost clarity, or became uncertain.
I explored what an ideal flow would look like if those moments were handled differently. Where friction existed, replace it with clarity. Where work was repetitive, reduce it. Where decisions felt uncertain, make them immediate. That became the brief.
This became the basis for the future workflow, defining how the experience should feel end to end, independent of specific features or implementations.
The system absorbs the effort that previously fell on users. Nine manual steps become seven guided stages. Weeks of interpretation become hours of decision-making.
Reyda was designed to address the points where the workflow consistently broke down. Instead of layering features onto existing steps, the focus was on how information flows through the product and where effort sits.
Three principles shaped the structure.
Tenders across EU platforms are aggregated and filtered based on relevance and capability. Instead of searching and manually narrowing options, teams are presented with opportunities that already align with their profile.
Requirements are extracted and mapped against company capabilities as soon as documents enter the system. Matches, gaps, and critical signals are surfaced immediately, removing the need for manual interpretation before qualification.
The system continuously processes documents, cross-references capabilities, and tracks changes in the background. Users are only brought in where a decision is required, rather than participating in every step of the workflow. (Keeping the human in the loop)
These principles reallocated effort away from the user and into the system, changing how work progressed from discovery through to submission.
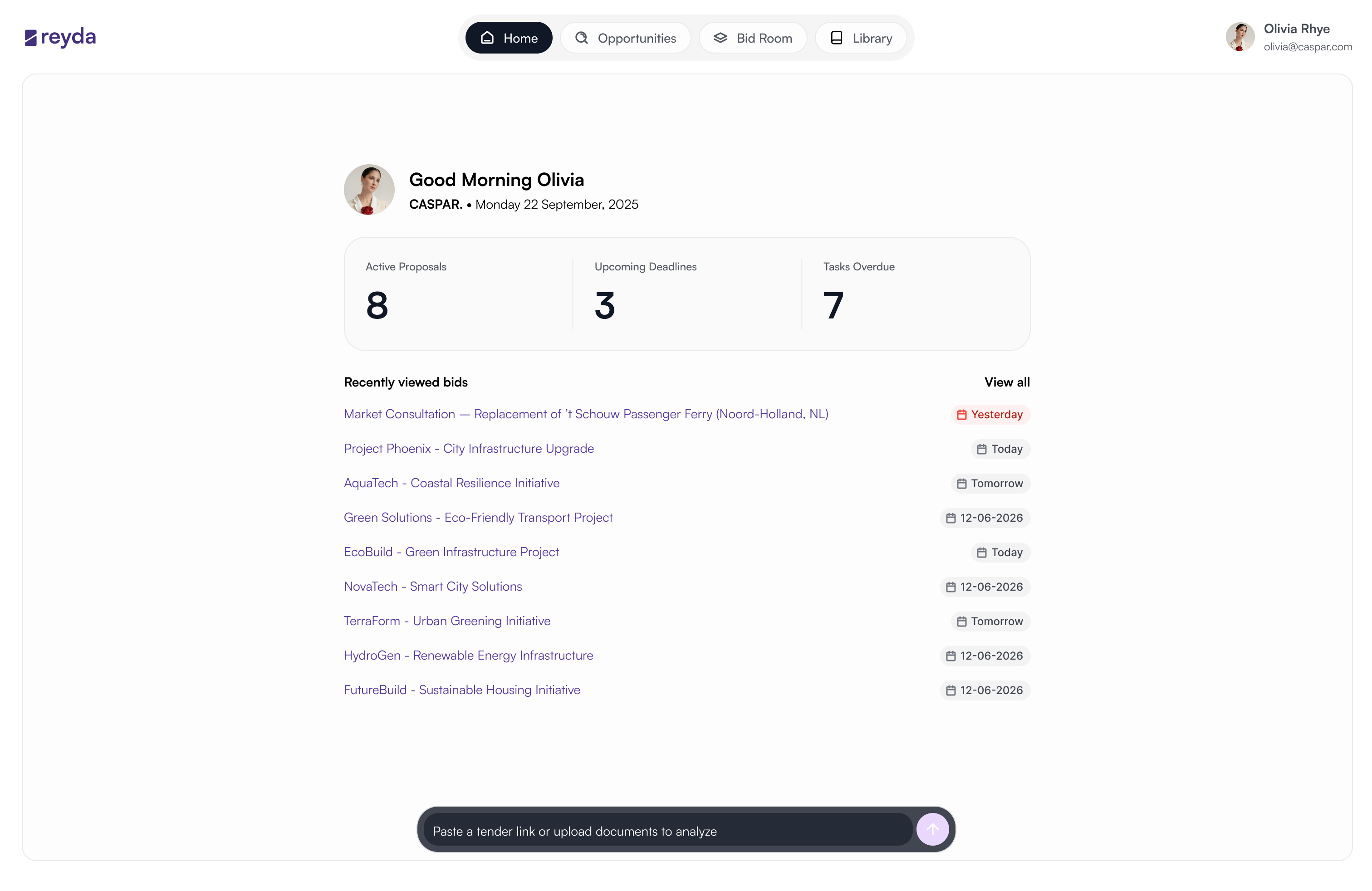
Active proposals, deadlines, and recent activity surfaced before anyone has to ask.
Fit-score sits at the top of every card. The go/no-go question is answerable without opening a document.
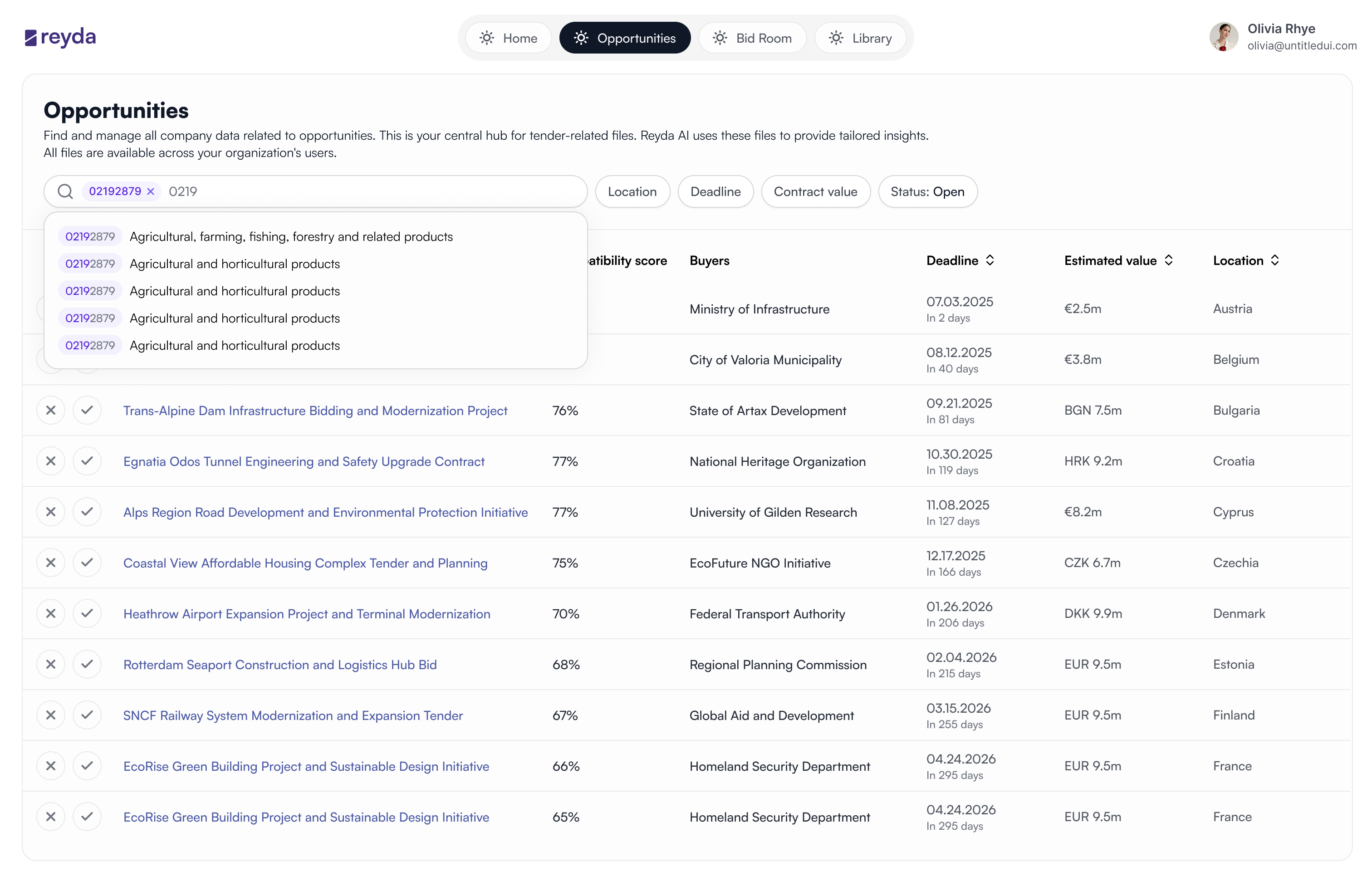
Documents restructured into named, navigable sections — even when the original had none.
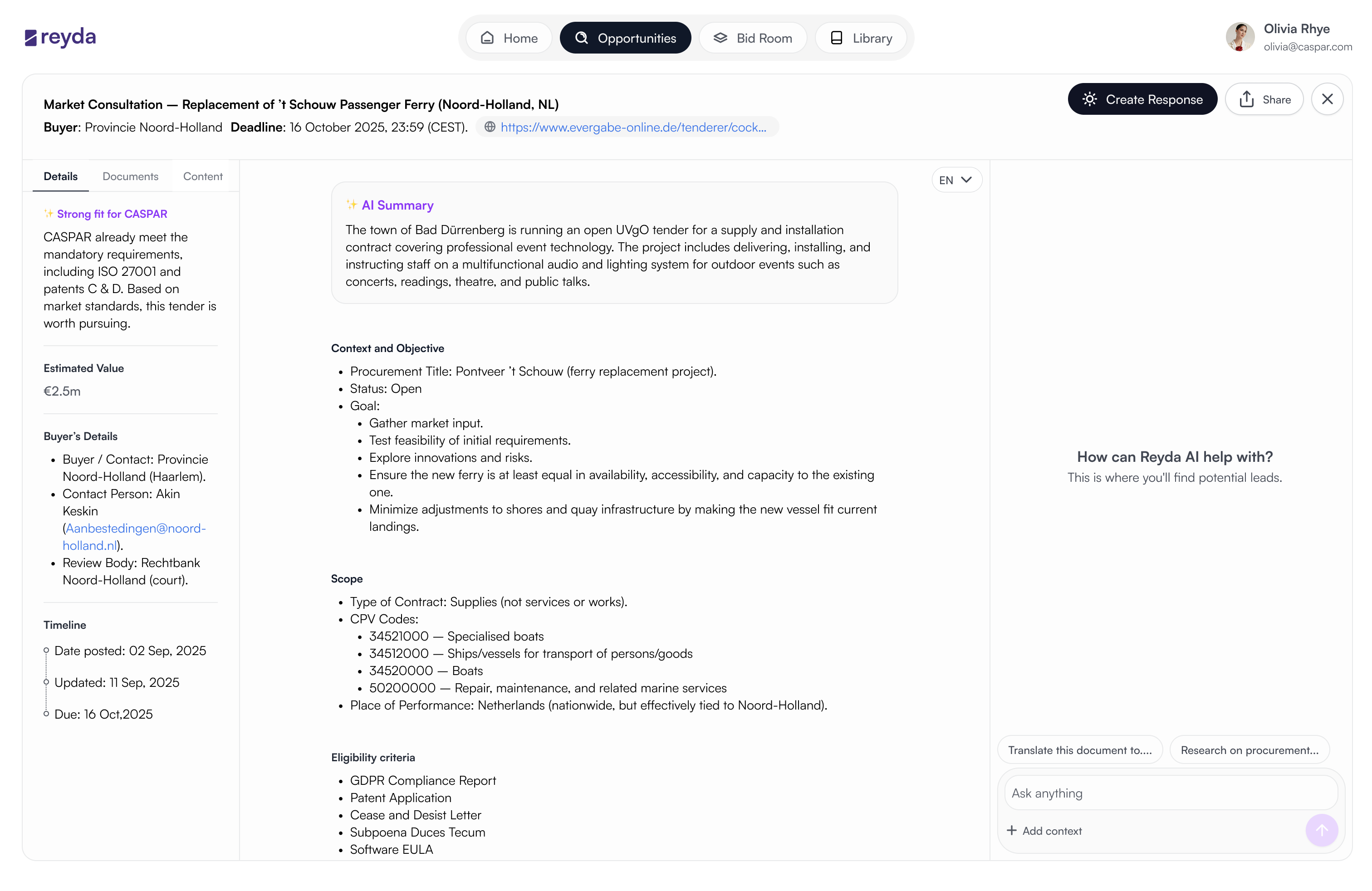
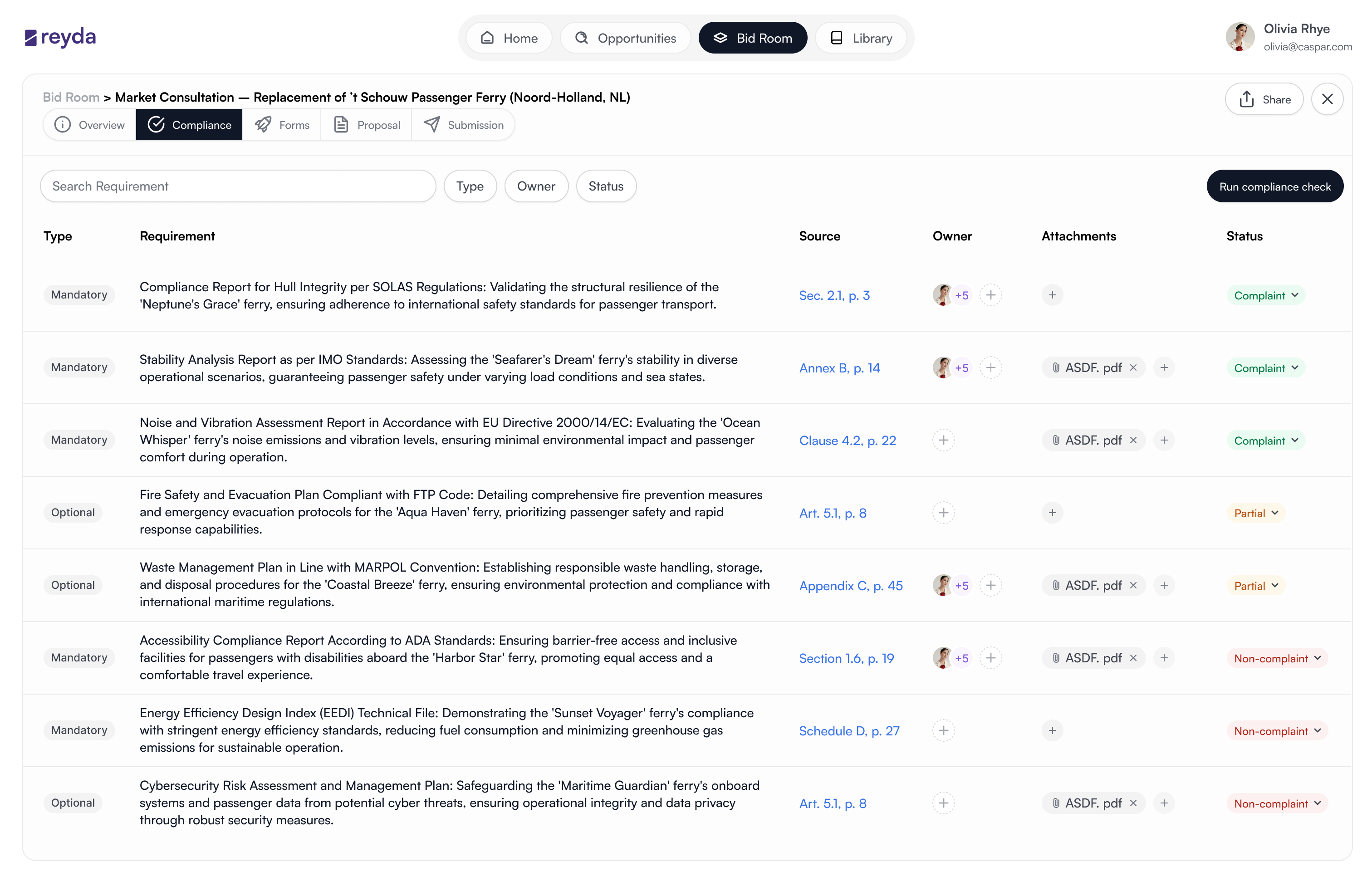
Three distinct layers: requirements, obligations, risks. Users triage before reading in full.
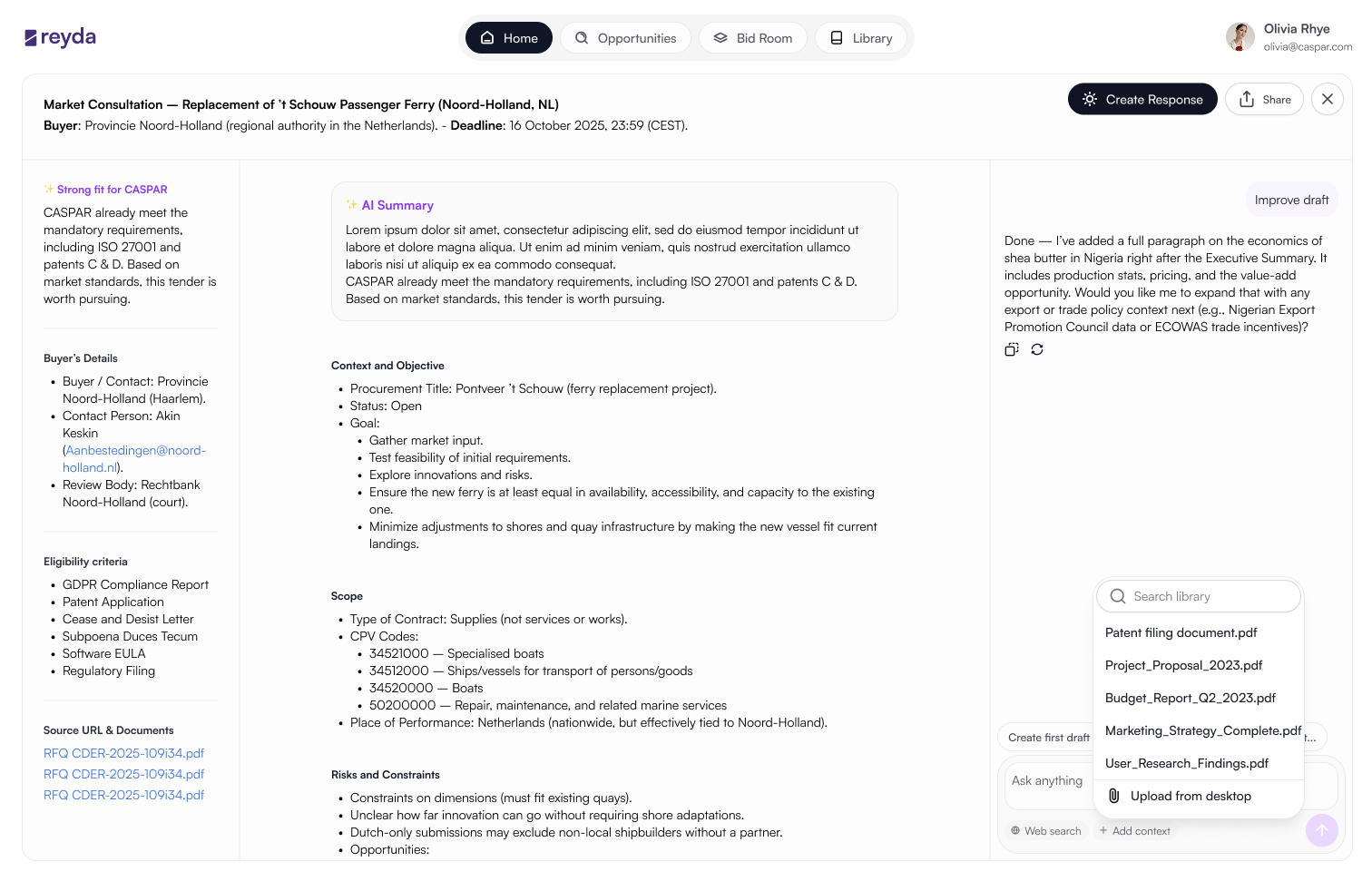
A direct line to the source. Summaries are verifiable, not taken on trust.
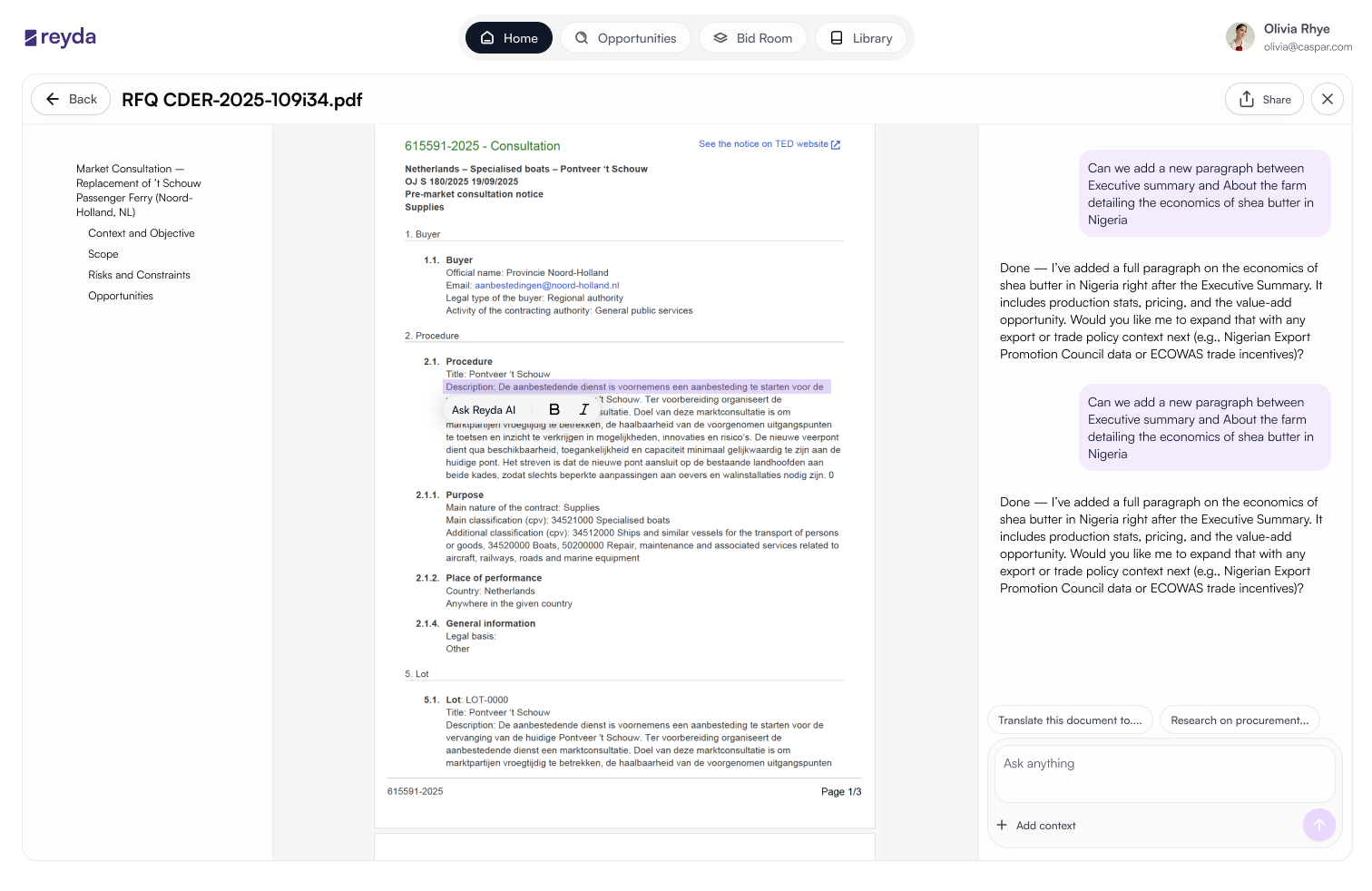
A persistent layer for company knowledge — drawn on continuously so qualification doesn't start from zero.
A status matrix, not a document. The binary qualification question gets a binary answer.
A completion map first. The full submission picture before entering anything individual.
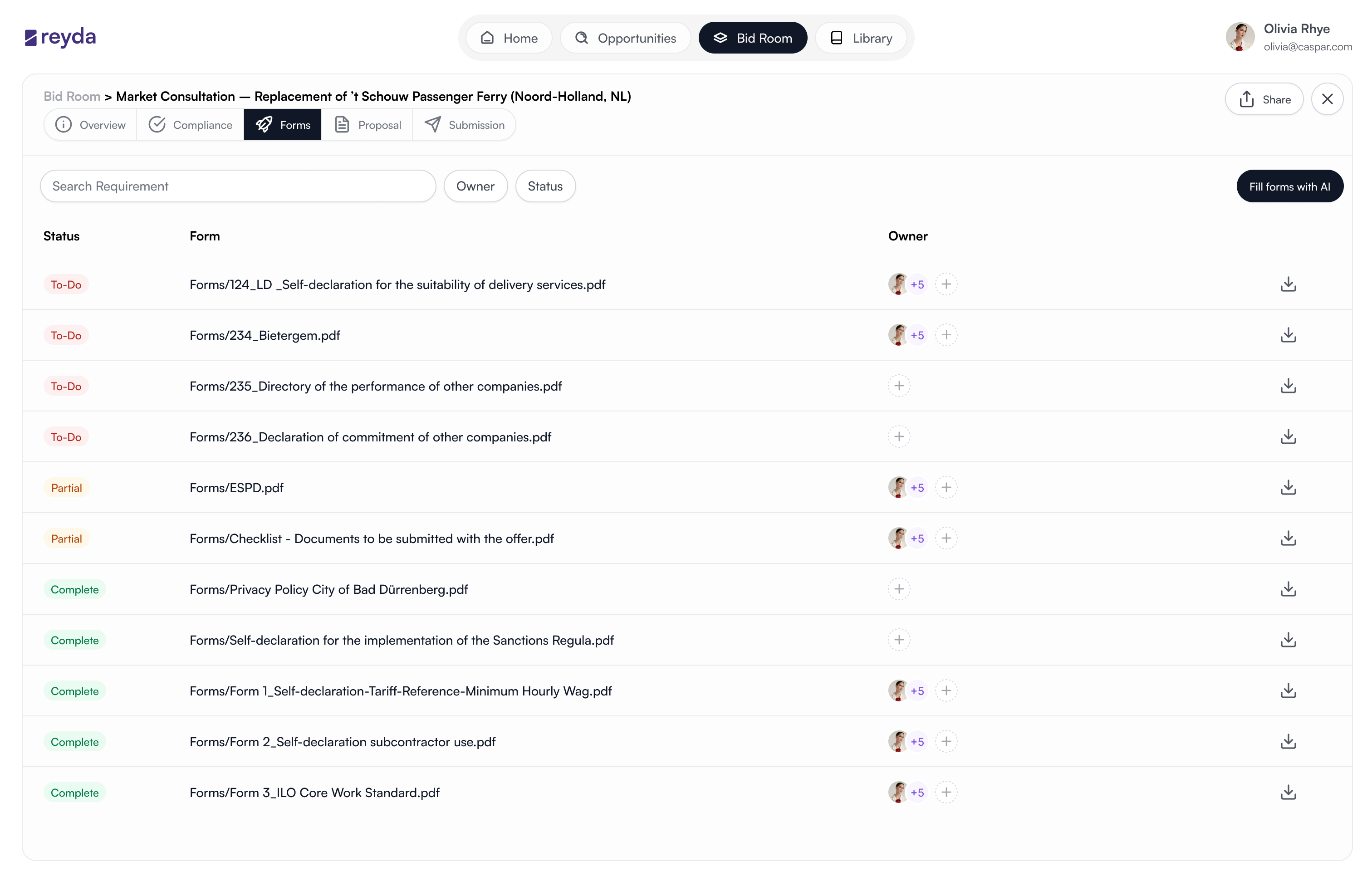
Pre-populated from Library, but the user makes the final call on every field.
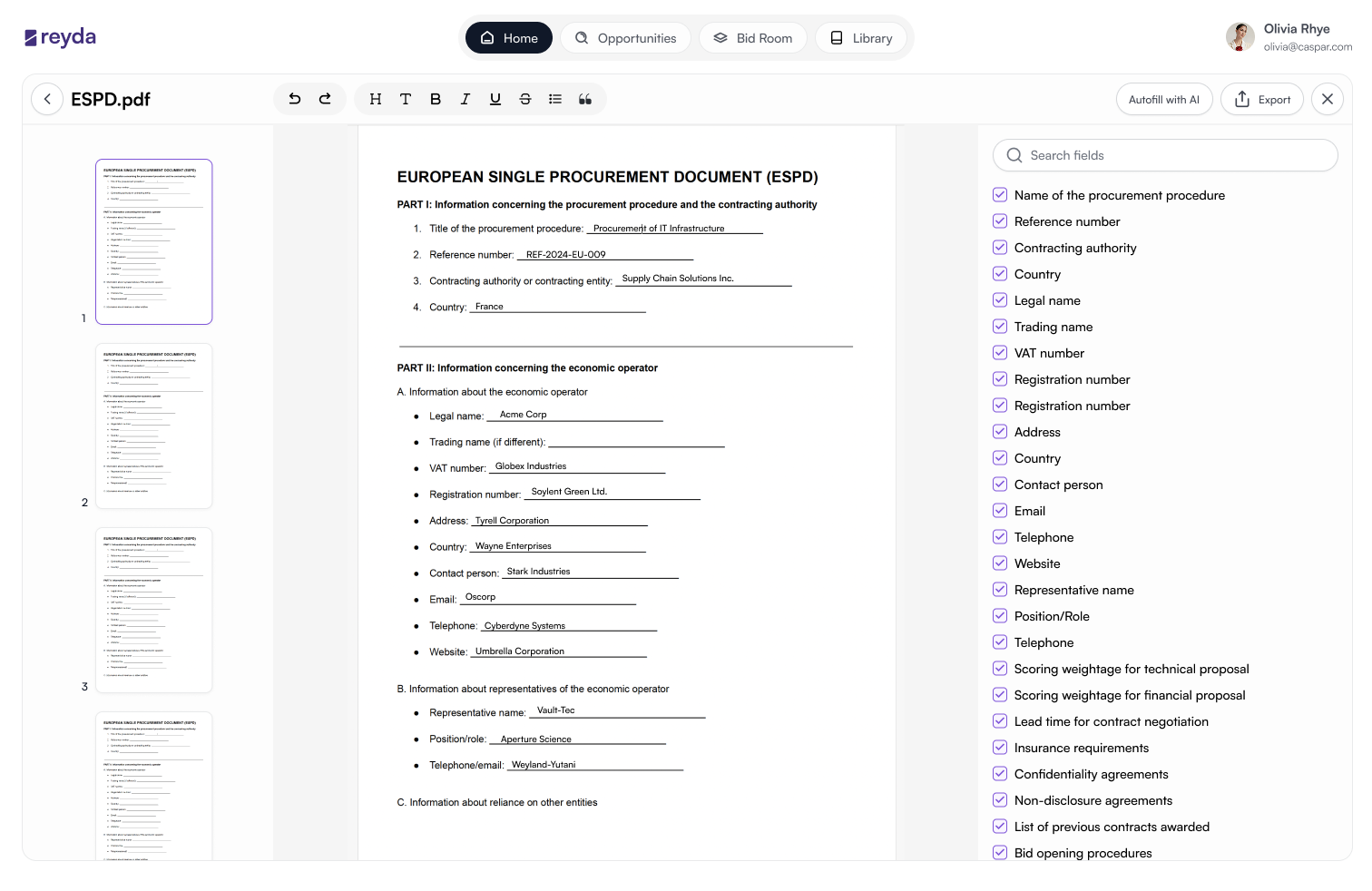
A structured scaffold to start from — removed as the user takes ownership.
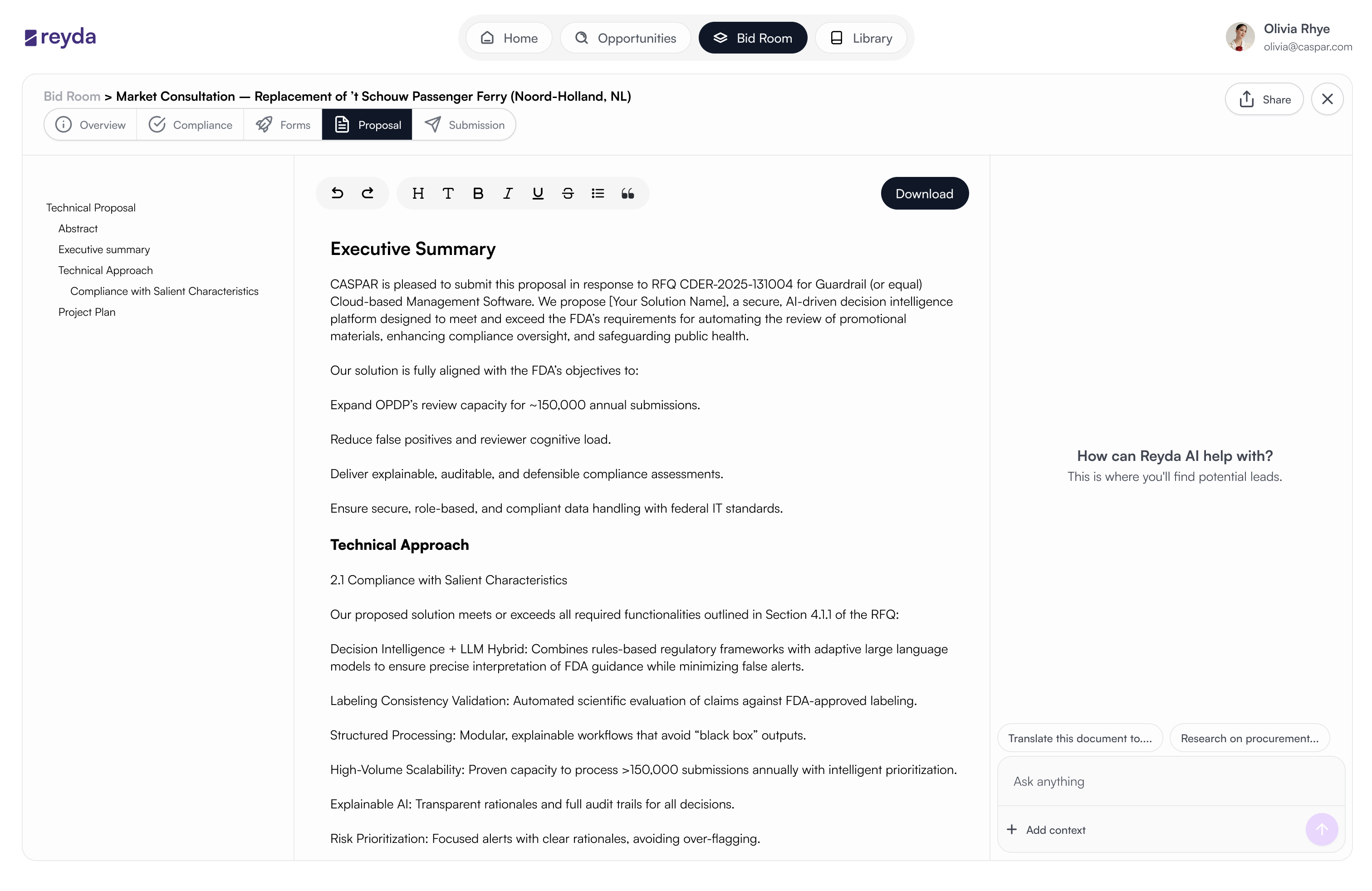
One tender, one deliberately linear flow: Overview → Compliance → Forms → Proposals → Submission.
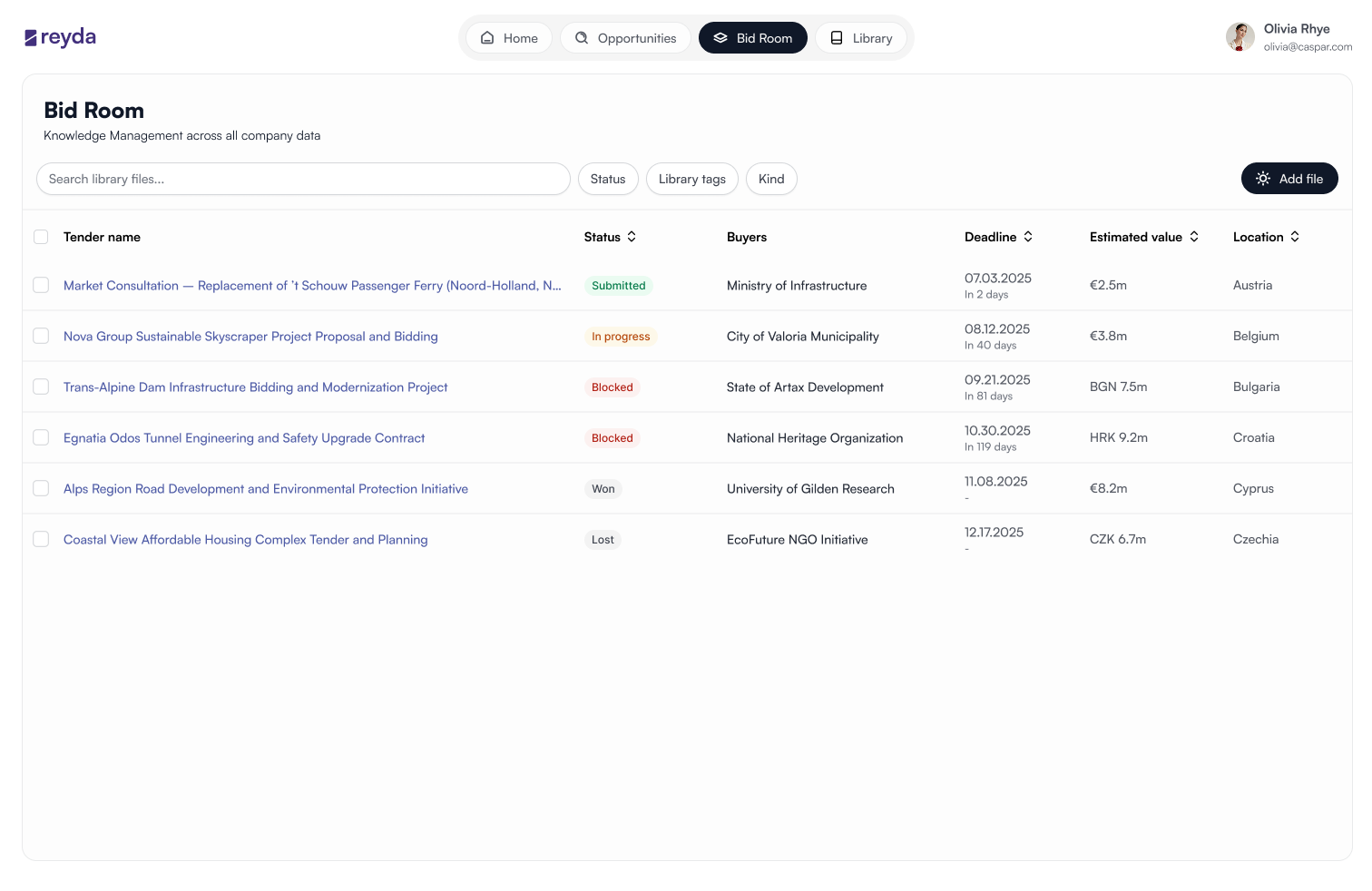
Each of these was a business call as much as a design call, since I was in both rooms at the same time.
We deliberately avoided overloading users with raw data. Early versions explored full document transparency, with every clause, cross-reference, and annotation surfaced, but this reintroduced the exact complexity we were trying to eliminate. The trade-off was uncomfortable, because some power users wanted the full document view back, and we chose not to give it to them. Structured clarity protects the 80% who are drowning in documents, even if it slightly constrains the 20% who know the landscape well enough to swim.
We focused on qualification rather than full automation of responses. It was tempting to ship AI-written proposals as the headline feature, since it demos well and is what the market was racing toward, but we chose the harder, less flashy direction. The aim was to remove the cognitive bottleneck at qualification and keep users in control of the words that actually go into a submission. Automated proposal generation was scoped out of the initial release to protect trust in the system's outputs, even though it meant giving up an obvious differentiator on the landing page.
We went deep on procurement instead of building a generic document-intelligence tool. A horizontal tool would have been easier to pitch to investors and easier to sell across verticals, but the insight was specifically about procurement's drop-off behaviour. Going deep meant a smaller addressable market in the short term and a much sharper product in the long term.
Rather than treat this as a finished product and ship broadly, I designed the rollout as a structured pilot, one company first and then five more, so the results would be measured against real workflows rather than self-reported preferences.
Before introducing the product, I shadowed a mid-sized procurement team over several weeks and tracked how long each stage of their existing tender workflow actually took. This is where the 2 to 6+ week current-state number comes from. The figure represents measured time across discovery, document review, requirement extraction, qualification, and response creation on live tenders.
I then moved the same team onto the product and held their working hours roughly constant. Instead of squeezing one tender into the window, the team was able to work through roughly eight times more opportunities in the same amount of time, because qualification shifted from days of manual interpretation to hours of structured decision-making. The bottleneck shifted from effort to opportunity selection.
Once the first pilot stabilised, I extended the rollout to five more teams with different sizes, sectors, and tender volumes. The improvement pattern held: teams consistently reached go/no-go decisions within hours, qualification uncertainty dropped, and drop-off on viable tenders fell sharply. Variations across teams were mostly about habit and tolerance for AI-assisted decisions rather than about whether the system worked.
The most important signal was behavioural. Instead of starting with documents, users started with clarity. The qualification step, which previously caused the most friction, stopped being a bottleneck, which is what ultimately reduced hesitation and moved teams from reactive to intentional.
A pattern emerged across the smaller organisations in the expanded rollout. Many were qualified in part but not fully, close to winning on their own merits and reliably excluded by requirements around team size, financial thresholds, or combined capability coverage. This pointed to a direction we had not originally scoped: consortium bidding, a mechanism for smaller companies to pool their qualifications, share documentation responsibilities, and compete together for tenders that none of them could pursue alone. This is in active design rather than yet built, and the pilot made the case for it more clearly than any amount of upfront research could have.
Once the pilot data was stable, I compiled the findings, including the workflow timings, the 8× outcome, and the behavioural patterns, into a case for investment. I presented this directly to prospective investors, walking them through the problem space, the EU market context, and the product direction. Those conversations shaped how we framed the commercial opportunity and where we drew the boundary between what the pilot had validated and what the next phase would need to prove. The product secured early funding shortly after.
The challenge was not adding AI into the workflow. It was deciding where it should act, what it should structure, and what it should leave alone.
The hardest part was finding that balance: too much structure removed control, and too little left users doing the work themselves.
Success was not measured by output, but by whether users reached clarity faster and could move forward with confidence.
The Library was not part of the original structure; it emerged from a gap. Without persistent company knowledge, every tender started from zero, and adding it as a foundational layer changed how the system reasoned about new opportunities and removed repeated work across the workflow.
Owning design, research, and a meaningful part of the front-end made it possible to move quickly and keep decisions aligned, but it also meant the system was limited by how much I could hold in my head at once.
The next version of this work needs shared ownership, not because this approach failed, but because it is the reason it worked and the reason it cannot scale further.