Lead Product Designer
Absorbing government data
Turning a 3–5 month partner data handoff into a self-service validation workflow
Turning a 3–5 month partner data handoff into a self-service validation workflow
From ~60 days to ~2 weeks per partner onboarding
Specifications shared up front and validation moved to upload, so partners arrive with the right data the first time. The 60-day intake compressed to about two weeks at most.
Email back-and-forth eliminated
Every clarification, status check, and correction moved into the system. The data team stopped acting as a human middleware layer between the pipeline and the agency.
Partners can describe pipeline stages without reference material
After two weeks in the system, government-side analysts can talk through where their data is, what's been validated, and what's blocking the next stage, without opening docs.
Data team reclaimed time for the model
With manual conversion and status emails removed, Dan's team shifted from middleware work to research that improves the model. Onboarding additional countries no longer caps on team capacity.
I was brought in on what was framed as a crop detection problem. After mapping the system with the Director of Data, I reframed it as a partnership-scaling problem gated by an invisible validation pipeline, the ML model wasn't eroding trust, the 40-day manual intake process was.
This work sits in the data layer of Agriculture Intelligence, the connected sources section that feeds the platform's crop monitoring, scenario planning, and food security dashboards. The platform's commercial value depends entirely on reliable, country-specific ground truth data. Without a clean, scalable intake process, the platform cannot grow to new crops or new government partners.
Rather than redesign the full ingestion stack, I scoped a read-only MVP that makes the quality pipeline observable: where a submission is, what's happening to it, and what it needs to progress. I produced the service blueprints that got the team aligned on the before/after, negotiated structured error surfaces from engineering, and moved into implementation using a design-directed code generation workflow, shipping reviewable React components alongside the design, not after it.
The trust gap wasn't abstract. It was 40 days of manual work, per submission, every time.
Agencies are blind to the status of things.
Every submission is a custom handling job.
Scaling to new crops or regions means restarting from scratch.
An eye-level read of the eight stages — where Kibet and Dan are at each step, and how a single onboarding stretches across 3–5 months without ever returning a reusable artefact for the next partner.




Kibet, a ministry admin at the Ministry of Agriculture, finishes a meeting with the Agriculture Intelligence platform team. They need ground truth data to onboard the country onto the platform.
During the meeting, they discussed field boundaries, crop types, and location data, but the specifics were vague. No one shared a template or defined exactly what formats or fields were required.
Kibet leaves the meeting wanting to get this right. The platform promises real value for the ministry's agricultural programs. But he's not quite sure where to start.
Kibet gathers all the ground truth data the ministry has collected over the years. It sits in multiple formats, spreadsheets, shapefiles, and PDFs from field officers.
He doesn't know which format the platform needs, so he packages everything together. Some files use local crop type names; he's unsure if they match what the platform expects.
He reviews the data manually, but with thousands of records across multiple regions, he can only spot-check. He hopes it's enough.
Kibet sends the data to the Agriculture Intelligence team. He feels uncertain, there was no way to validate whether the data was complete or correct before submitting. Now he waits.
There's no way to check submission status or get feedback. He moves on to other work, hoping he won't hear back with a long list of problems.
On the other side, Dan and the data team receive the submission. Dan opens the files and immediately sees the challenge ahead.
Dan and the data team begin processing. The files arrive in mixed formats, CSV, shapefiles, scanned documents. Column names vary. Required fields are missing.
They spend at least 40 days converting everything into a standardised format. Then they validate content against the contract, checking crop types, field sizes, coordinates. They find mismatches, local naming conventions, impossible values. Each issue is flagged for manual correction.
Dan and the team move into verification. Each record is manually checked against satellite imagery to confirm that what is claimed matches what is on the ground.
They review field boundaries polygon by polygon, checking that recorded farmland isn't actually a road, a building, or a mountain. For an entire country's worth of data, this takes days. The team is skilled at this, but Dan knows their time could be spent on higher-value work. Instead, they're verifying data.
The team discovers gaps. Entire regions are missing field records. Some crop types have too few samples. They search for external data sources to supplement, some are available; others aren't.
For gaps that can't be filled externally, they go back to Kibet. Kibet receives the request and starts looking. He thought he had sent everything. Now he's digging through records again.
Kibet sends additional data. The team validates it again, standardising, checking content, verifying against imagery. More questions arise. Another email to Kibet. Another round of waiting. Each exchange adds days.
Neither side has visibility into what's still missing or how close they are to completion.
The ground truth data is finally clean and ready for use. Dan and the team have spent over a month on what should have been a straightforward intake process.
The platform can now deliver value to Kibet's ministry. But when the next partner onboards, or this ministry expands to new crops or regions, the cycle starts again from scratch.
The user experience, across both sides of the partnership, collapsed to two sentences:
I was inside the digital government, having conversations with the in-house data team, the Director of Data, and the people who actually ran the data intake. From there, in-person interviews with the ministry admins on the government side — the Kibet-type users — surfaced the partner-side pain the internal team only saw indirectly. The same themes returned across every conversation and every step of the current state. Drag any note around — they live as a pile, not an ordered list, because that's how they came up.
No handoff spec, just meetings
Every onboarding starts with a meeting. No template, no schema doc. Kibet leaves the call and starts guessing what's needed.
A 40-day black box
Once data is submitted, Kibet hears nothing for ~40 days. No status, no progress, no signal it even arrived intact.
No ownership on agency side
After submission, no one inside the partner ministry feels accountable. It becomes Dan's problem to chase down corrections.
Every submission resets the clock
No reuse between rounds. The fifteenth submission costs the team the same hours as the first. Zero compounding learning.
~60 days to onboard one partner
Two months from first call to a clean dataset. Most of that is waiting on documents that nobody flagged were even required.
Communication runs on email threads
No shared status. No queue. No system of record. Every clarification is a new email reply-all that someone has to keep alive.
Skilled people on manual conversion
Dan's team spends days doing format conversion and column renames a script should handle. Senior data work, not data wrangling.
Errors surface late
Validation happens at the end of the pipeline, not at upload. Bad geometry or wrong CRS only fails after the data team has touched it.
"Mundane" work as middleware
The Director's word: the team is acting as middleware between the pipeline and the agency. Manually emailing status updates that should be automatic.
Partner onboarding doesn't scale
The 40-day intake scales linearly with partners. The data team doesn't. Adding the tenth partner means breaking the team.
"Good data" is undefined
Partners can't validate before submitting because nobody has written down what "valid" means. It only emerges after rejection.
Kibet wants visibility, not handholding
"I just want to know it landed and what's happening." The ask isn't fancier UX, it's just a status the partner side can see.
Two users. Tightly coupled goals. The case for read-only visibility only makes sense when you see their pain as a single coupled system, Kibet can't standardise without specifications, and Dan can't stop doing custom handling until specifications exist and are enforced.
The wall between them is the thing that takes 40 days. Kibet can't standardise without specifications; Dan can't stop custom handling until specifications are enforced.
Four themes kept surfacing in every interview and every step of the current state: no specifications at handoff, no visibility after submission, skilled people doing automatable work, and zero reuse across submissions. None of those are UI problems. They are lifecycle problems, and that changed what I was actually designing.
So I reframed the brief from "redesign the upload flow" to "make the quality pipeline observable and self-service." That reframe changed the unit of design from a form to a lifecycle, the user from a single admin to a partnership, and the measure of success from submission UX to partnership throughput.
Six stages, two decision points. Most steps run on the system; two are deliberately the user's call — that's the design work. Where everything is automated, and where Kibet still needs to step in. The architecture below is what we converged on with the Director of Data and Director of Product: the partner-facing surface is the read-only window into this pipeline.
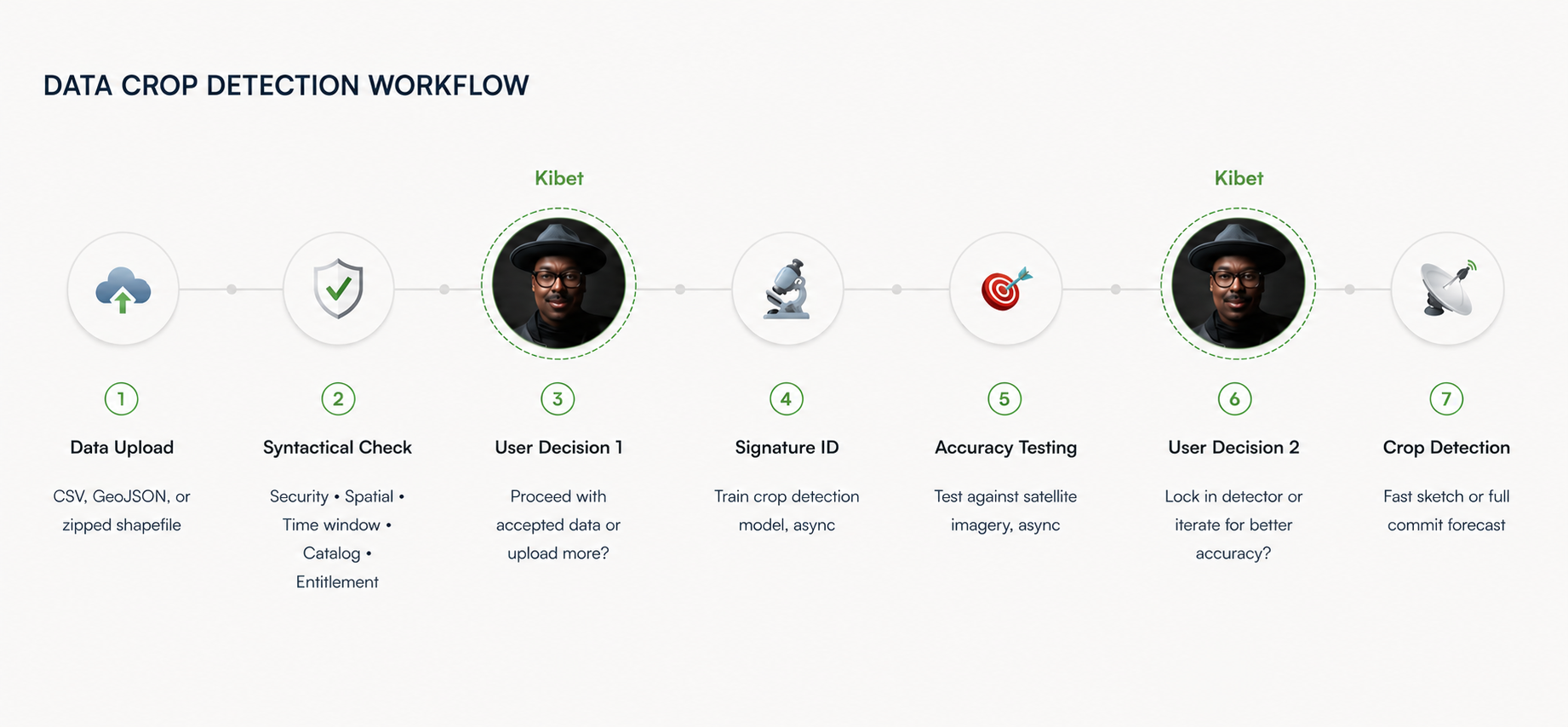
After contract close and as part of onboarding, Kibet receives access credentials for Agriculture Intelligence. He logs in and is guided to the ground truth admin area, where he sees a clear overview of the ground truthing process.
He also sees the precise data requirements he needs to meet. Using those requirements, he prepares the crop data and uploads.
In the background, the system runs a security scan on the file first, then checks the data format. Kibet can see the status of what is happening and receives precise feedback.
a) If data passes, he gets confirmation of acceptance and knows his work is done for now. b) If not, he sees exactly what to fix, making corrections and re-uploading as needed. No guessing, no delays.
After format is accepted, the system continues into data quality check. Kibet can see the workflow has moved into data quality. a) If the data quality checks out, the system moves on. b) If there's a problem, the system flags it, Kibet sees exactly which crop or region needs more data or where corrections are required. Instructions are clear, actionable, and free of jargon.
The system moves into baseline detection. Once the unique spectral signature of the crop is identified, the system runs testing and produces an accuracy result. Kibet receives the result and reviews.
a) If the results satisfy Kibet, he gives the go-ahead for full scale detection. b) If not, the workflow shifts into improvement, adding more input data or Dan refining the detection model, then rerunning.
After approval, the system kicks off full scale detection and yield/production forecasting. Optional: if needed, Kibet can still upload additional data to improve accuracy over time.
Dan Letterman is not involved in the routine workflow anymore. Because routine work is handled through the process, he spends most of his time improving the model and performance, and only steps in when needed.
What previously required weeks of fragmented manual work is now:
The shift is not speed alone. It is clarity, confidence, and continuity for both sides of the partnership.
The design goal is clarity across levels: what's happening across the board, where the system is, where the user doesn't need to step in, and where they do. Kibet is a ministry admin, not a data analyst, every trade-off resolves toward clarity over density.
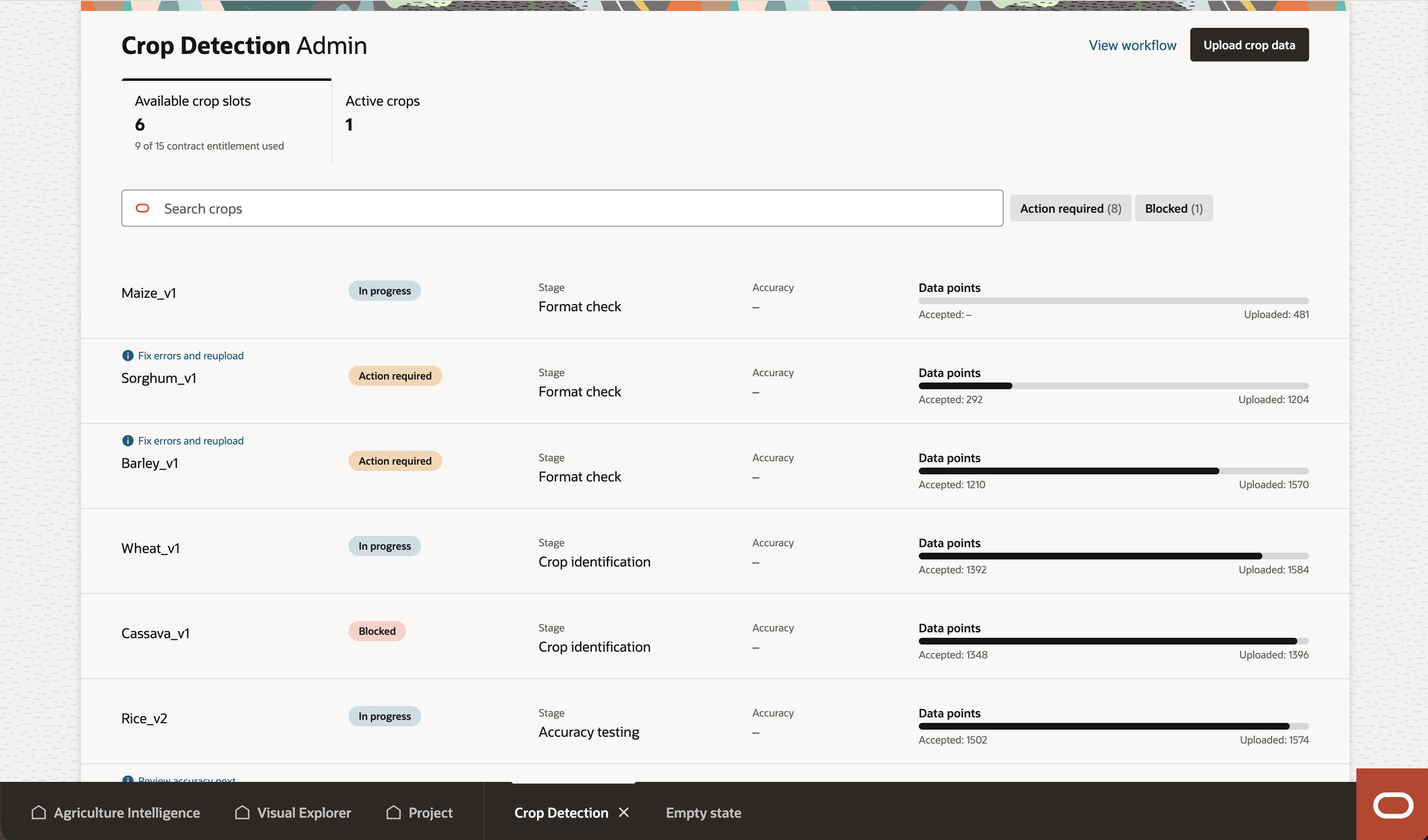
A submission is tied to one crop, so the table is really a view of crops in flight. The work was in simplification, stripping it down to what matters: which crop, which version, is it active or inactive, is it processing, where does the user need to act.
The "needs action" surfacing carries the two user decision points as first-class items, not buried sub-states. Users filter quickly to the rows that need them; everything else lives behind the row.
V1 is read-only, so navigating to a detail page is wasted motion. Opening a submission in a drawer keeps the list in context and lets users compare without losing their place.
Locked-in crops count against a contract cap (e.g., 8 crops). The UI surfaces crops remaining up front, because that number directly shapes whether a user locks in a noisy detector or iterates for a better one. It's a small element doing outsized work.
I refused to ship generic "validation failed" states. Each gate in the pipeline, spatial validity, time window, crop catalog, signature quality, needs its own failure vocabulary in the UI, because the user's next action differs. A spatial failure means "check which polygons fell outside your country boundary"; a crop catalog failure means "your local crop name doesn't match our approved catalog." This required engineering to return structured error data rather than human-readable strings.
Three axes were set before design began. Here is how each played out — what the work delivered against each measure.
Partner onboarding time compressed materially, from a 3–5 month cycle toward something the data team can sustain as partnerships scale.
Kibet, the ministry admin, can diagnose and resolve data issues without opening a support thread.
Dan, the data team lead, stops owning routine format conversion and manual verification, and reclaims time for model improvement.
AI is letting me extend the design role into front-end implementation. I no longer hand off static mocks; I ship reviewable React components alongside the design, not after it. Three phases, each using AI at a different level of fidelity — wireframing for breadth, design-system reconciliation for honesty, code generation for handoff.
Before touching the design system, I write out what the UI needs to expose and what decisions a user faces. I take that into Figma Make and generate wireframe directions, then pull the output into a Figma file, adjust what's wrong by hand, and feed the refined version back through Figma Make. The loop runs until the flow feels right. AI for breadth and speed; Figma for precision where generation oversimplifies.
Compressed wireframing from days to hours. The value isn't in any single frame, it's in how many directions the loop lets me discard quickly.
↳ Figma Make prompt → generated wireframe → hand-refined version.
Once the exploration loop settles on a direction, I move into the existing Oracle design system. This is deliberately unglamorous: which tokens exist, which components can be composed into what I need, what has to be net-new. Fast-and-loose wireframes become production-grounded. Every component decision made here becomes the handoff spec, including what I'm asking engineering to build vs. what already exists.
The design system pass is where speed meets honesty. It tells me, before engineering is involved, what's actually buildable in the current sprint.
↳ Wireframe mapped against Oracle design system tokens and components.
The reconciled design moves into Codex to generate React components against our existing component library. I treat the output the way I'd treat a junior designer's first draft, checking whether state coverage is exhaustive, whether hierarchy reflects user priorities, whether the generated component would survive real data. I've built reusable prompt scaffolds encoding the state vocabulary, design tokens, and error grammar, so the third component inherits everything the first learned.
Engineering receives something that already works. Their job becomes integration, not reconstruction, and the UI back-and-forth that usually happens in review collapses substantially.
↳ Codex prompt + generated React component output side-by-side.
This isn't a crop detection UI. It's the quality gate that determines whether the platform can scale partnerships at all. Today, every new government partner costs the data team a month of manual work, and every expansion restarts the cycle. The MVP attacks the three things that make that cycle expensive:
Working on this also pulled me, as a designer, into territory I hadn't owned before, service architecture, data pipelines, validation gates, engineering negotiation. What I learned is that the strongest design work in a complex system is rarely about the surface. It's about understanding where the friction actually lives, often somewhere you can't see from the UI, in a handoff between two teams or a missing decision-rights boundary, and designing for that. By the time the design took its final shape, most of the work had already happened in conversations about what the data team would auto-validate, what engineering would gate, and what the partner ministries could be trusted to standardise. UX work that stops at the screen leaves the hardest problems untouched.
The goal was never to make the upload UI nicer. It was to make the pipeline honest about what it's doing and who it's waiting on.

"As a government agency, I want to actively contribute our knowledge and inputs to the Agriculture Intelligence platform, so that we can get meaningful value from the platform."

"As the Agriculture Intelligence data team, we need to receive clean, standardised, consistent, and trustworthy ground truth data so that we are confident in the output we deliver to clients and can spend more time on work that meaningfully improves outcomes."